Evangelos Kazakos1, Arsha Nagrani2, Andrew Zisserman2 and Dima Damen1
1University of Bristol, Dept. of Computer Science, 2University of Oxford, VGG
Outstanding paper award at ICASSP 2021!
Abstract
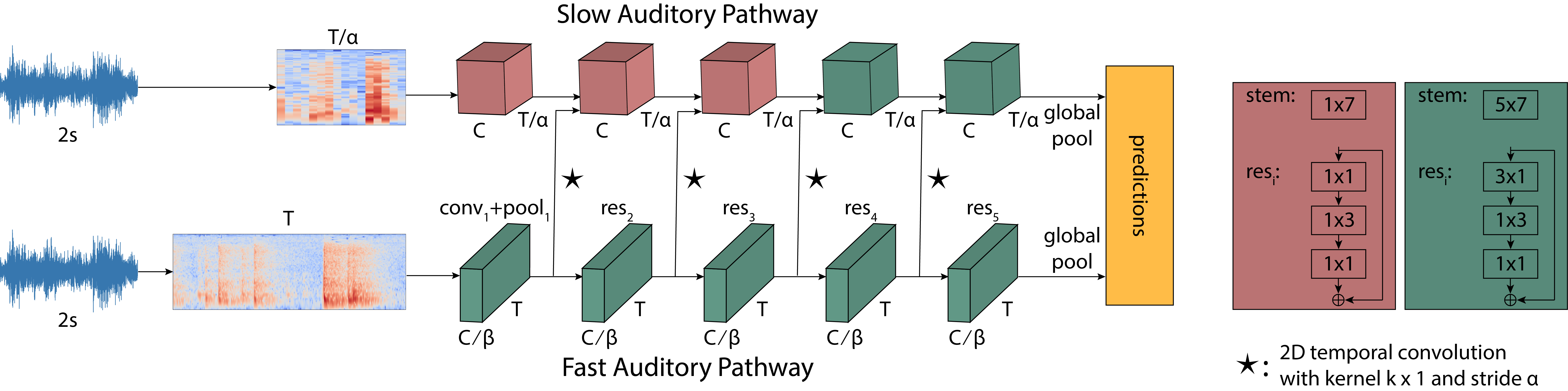
We propose a two-stream convolutional network for audio recognition, that operates on time-frequency spectrogram inputs. Following similar success in visual recognition, we learn Slow-Fast auditory streams with separable convolutions and multi-level lateral connections. The Slow pathway has high channel capacity while the Fast pathway operates at a fine-grained temporal resolution. We showcase the importance of our two-stream proposal on two diverse datasets: VGG-Sound and EPIC-KITCHENS-100, and achieve state-of-the-art results on both.
What is learnt from each stream?
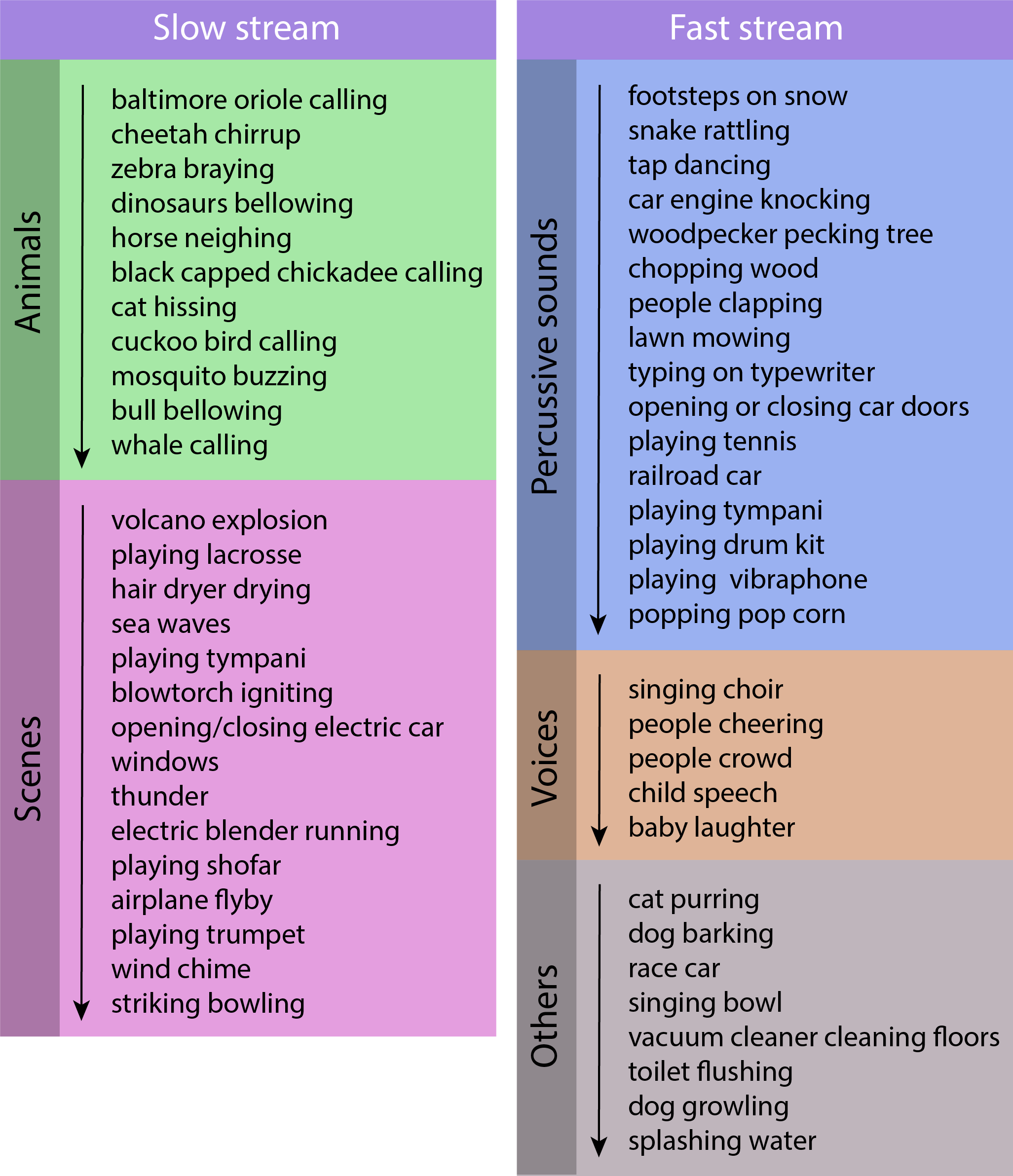
The figure below shows classes of VGGSound for which Slow is significantly better than Fast (left) and vice-versa (right). Slow performs better for animals and scenes with distinct frequencies, showcasing the enhanced spectral modeling capabilities of Slow. Fast is better at predicting classes with percussive sounds, demonstrating that it focuses on learning temporal patterns.
Video
Downloads
- Paper [arXiv] [IEEE Xplore]
- Code and models [GitHub]
- ICASSP slides [Link]
Bibtex
@INPROCEEDINGS{Kazakos2021SlowFastAuditory,
author={Kazakos, Evangelos and Nagrani, Arsha and Zisserman, Andrew and Damen, Dima},
booktitle={IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
title={Slow-Fast Auditory Streams for Audio Recognition},
year={2021},
pages={855-859},
doi={10.1109/ICASSP39728.2021.9413376}}
Acknowledgements
Kazakos is supported by EPSRC DTP, Damen by EPSRC Fellowship UMPIRE (EP/T004991/1) and Nagrani by Google PhD fellowship. Research is also supported by Seebibyte (EP/M013774/1).